There Is No General First Amendment Right to Distribute Machine-Learning Model Weights
Unlike source code, which humans use to express ideas to each other, model weights function primarily as machine-readable instructions.

Published by The Lawfare Institute
in Cooperation With
![]()
In response to last year’s executive order on artificial intelligence (AI), the National Telecommunications and Information Administration just finished soliciting comments in preparation for a report on “the potential risks, benefits, other implications, and appropriate policy and regulatory approaches to dual-use foundation models for which the model weights are widely available.” One notable comment, led by the Center for Democracy and Technology and Mozilla and signed by leading digital civil-society organizations and top academics in computer science and law, strongly supports openness and transparency in machine-learning models.
In particular, and in response to reporting that the Commerce Department may be considering imposing export controls on certain AI systems, the comment warns that “courts may find that export controls on the publication of model weights implicate the First Amendment” and “unconstitutionally hinder scientific dialogue.” The comment cites a line of cases holding that computer source code is speech protected by the First Amendment. The implication, then, is that model weights are also protected by the First Amendment.
I think this is wrong. Unlike source code, which humans use to express ideas to each other, model weights function solely as machine-readable instructions. A careful look at the cases that first established that source code could, under certain circumstances, be First Amendment-protected speech, demonstrates why such protections should not extend to model weights. (For another analysis of this issue, see this recent draft by Doni Bloomfield at 24–32.)
In the late-1990s, litigation in the U.S. Court of Appeals for the Ninth Circuit, also in the context of export controls on computer technology, first addressed the question of whether computer code was speech for the purpose of First Amendment protections. Daniel Bernstein, then a Berkeley mathematics doctoral student, developed an encryption algorithm that he called “Snuffle.” Bernstein wanted to share his algorithm, but, because of export restrictions that were in place on encryption systems, he needed to first get permission from the State Department, which the State Department denied, both as to the source code for Snuffle and also the academic paper in which Bernstein described his algorithm.
Bernstein sued and won in district court, which held that not only was Bernstein’s academic paper speech for First Amendment purposes (and thus the State Department’s export restriction was an unconstitutional prior restraint), but so was the Snuffle source code. The court held that source code, which is written in a human-readable programming language, was no less expressive than other forms of First Amendment-protected expression, such as mathematical or musical notation, also used to communicate ideas and messages. The district court even went so far as to argue that object code—the literal 1s and 0s that source code is compiled into to run on hardware—was First Amendment-protected “language,” since, as it argued, “when the source code is converted into the object code ‘language,’ the object program still contains the text of the source program.”
On appeal, the Ninth Circuit also ruled for Bernstein, though on somewhat narrower grounds. Focusing specifically on source code, and explicitly disclaiming any holding regarding object code, the court emphasized that “cryptographers use source code to express their scientific ideas in much the same way that mathematicians use equations or economists use graphs,” which are protected by the First Amendment, and that, “by utilizing source code, a cryptographer can express algorithmic ideas with precision and methodological rigor that is otherwise difficult to achieve.”
The court further rejected the government’s argument that, even though source code was expressive, the export control restrictions were constitutional because they targeted the functional, rather than expressive, aspects of the code—that is, its ability to be transformed into running encryption software. The court emphasized the distinction between source and object code, noting that, “while source code, when properly prepared, can be easily compiled into object code by a user, ignoring the distinction between source and object code obscures the important fact that source code is not meant solely for the computer, but is rather written in a language intended also for human analysis and understanding.”
The court also rejected the government’s argument that any degree of functionality removed otherwise expressive speech from the First Amendment’s scope. While not purporting to identify the specific point at which the functionality of code would outweigh its expressiveness for First Amendment purposes, it held that, in this case at least, the Snuffle source code was sufficiently expressive that, its functional uses aside, it fell within the protections of the First Amendment.
The Bernstein litigation then took a strange procedural turn. The Ninth Circuit granted the government’s petition for rehearing en banc and withdrew the panel opinion. But before the entire Ninth Circuit could rule on the case, the State Department settled with Bernstein, allowing him to post the Snuffle paper and source code.
Despite the Bernstein opinion lacking any legal force, it has been widely cited by other courts and its logic has had a pervasive influence. For example, in Junger v. Daley (2000), the Sixth Circuit, also addressing export control restrictions on encryption source code, held that source code enjoyed First Amendment protections because it is an “expressive means for the exchange of information and ideas about computer programming.” In Universal City Studios v. Corley (2001), the Second Circuit, citing Bernstein, held that the First Amendment applied to source code for a program that would decode the digital copyright protections on DVDs (although it upheld an injunction on the distribution of that source code as a legitimate “content-neutral regulation with an incidental effect on a speech component”). More recently, a judge on the Fifth Circuit cited Corley when dissenting from the majority’s upholding of an injunction against the distribution of computer-aided design (CAD) files for 3D-printed guns.
More generally, Bernstein has remained a foundational case in the imaginations of Silicon Valley and the broader digital civil society. The case featured prominently in journalist Steven Levy’s “Crypto,” the popular account of the “Crypto Wars” of the 1990s, and the Electronic Frontier Foundation (EFF), the leading digital civil-society organization, represented Bernstein and has described Bernstein as “a landmark case that resulted in establishing code as speech and changed United States export regulations on encryption software, paving the way for international e-commerce.” The “code is speech” slogan that Bernstein is often mistakenly boiled down to has played a key role in Silicon Valley’s techno-libertarian self-conception.
The reason that it’s a mistake to describe Bernstein’s logic as “code is speech” is because that goes far beyond what Bernstein actually said. As I have explained in another context:
Properly understood, Bernstein stands for a far more limited and, in the twenty-first century, downright banal proposition: Just because something is code does not mean that it is not speech. But whether a particular piece of code is speech for First Amendment purposes—most importantly, whether the government action regulates the speech’s expressive, rather than merely functional, aspect—is a separate question.
Nor can it be the case that literal “expressiveness” is sufficient to trigger First Amendment protections. As Orin Kerr observed nearly 25 years ago in a passage criticizing Junger:
The problem is that everything is “an expressive means for the exchange of information and ideas” about itself, and this is just as true in realspace as in cyberspace. For example, imagine that you have designed a new kind of padlock, and you wish to explain to me how the lock works. The best way to communicate that set of ideas is to give me one of the locks, let me play with it, take it apart, and see for myself how it operates. Sure, you could write a book that offers “a prose explanation” for how the padlock works, but I will learn much more by examining the lock first-hand. To borrow a phrase from the Junger court, access to the lock itself provides “the most efficient and precise means by which to communicate ideas” about it. And so it is for everything else in the world. Robbing a bank provides the most instructive way to teach someone how to rob a bank; kicking someone in the shins provides an excellent way of communicating the concept of kicking someone in the shins. So long as the only “expression” we are concerned with is information about the act or thing itself, that act or thing is bound to be an “an expressive means for the exchange of information and ideas” about it.
Kerr rightly takes this literal understanding of “expressiveness” as leading to absurd results, since it would eliminate the First Amendment’s distinction between speech and conduct, which, while sometimes murky, is a foundational boundary that keeps the First Amendment from applying to everything. Code is sometimes speech, but only when it is used in a way analogous to other traditional forms of communication—specifically, where the expressive function of the communication outweighs its functional role. The more that the dissemination of code differs in its form and function from normal linguistic conversation (whether in spoken or written form, and including symbolic analogues like scientific or musical notation), the less it should be considered expressive speech that falls under the First Amendment’s protections. (For a list of failed code-is-speech arguments, see this article by Kyle Langvardt at 152–54.)
This is admittedly a spectrum with no clear dividing line between speech and non-speech, but model weights still fall comfortably on the non-speech side of the line. The reason is that model weights are not generally used to express ideas among individuals but, rather, serve primarily as instructions to order machines to act, specifically to perform inference, the process of applying the model to a given input. In addition, model weights are not in a form that is suitable for communication between people, even skilled computer scientists and machine-learning engineers, analogous to the sorts of linguistic communications that are paradigmatic within First Amendment law. Typical models have billions of parameters—literally a multi-gigabyte-sized list of numbers. This isn’t, and likely never will be, the “Matrix,” in which characters could claim to “not even see the code.”
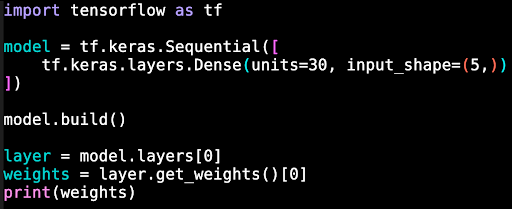
Compare, for example, the source code used to create a small toy model versus what the weights look like. Here’s the source code:
Here are the model weights (in a real model, the list of numbers would be many orders of magnitude longer):
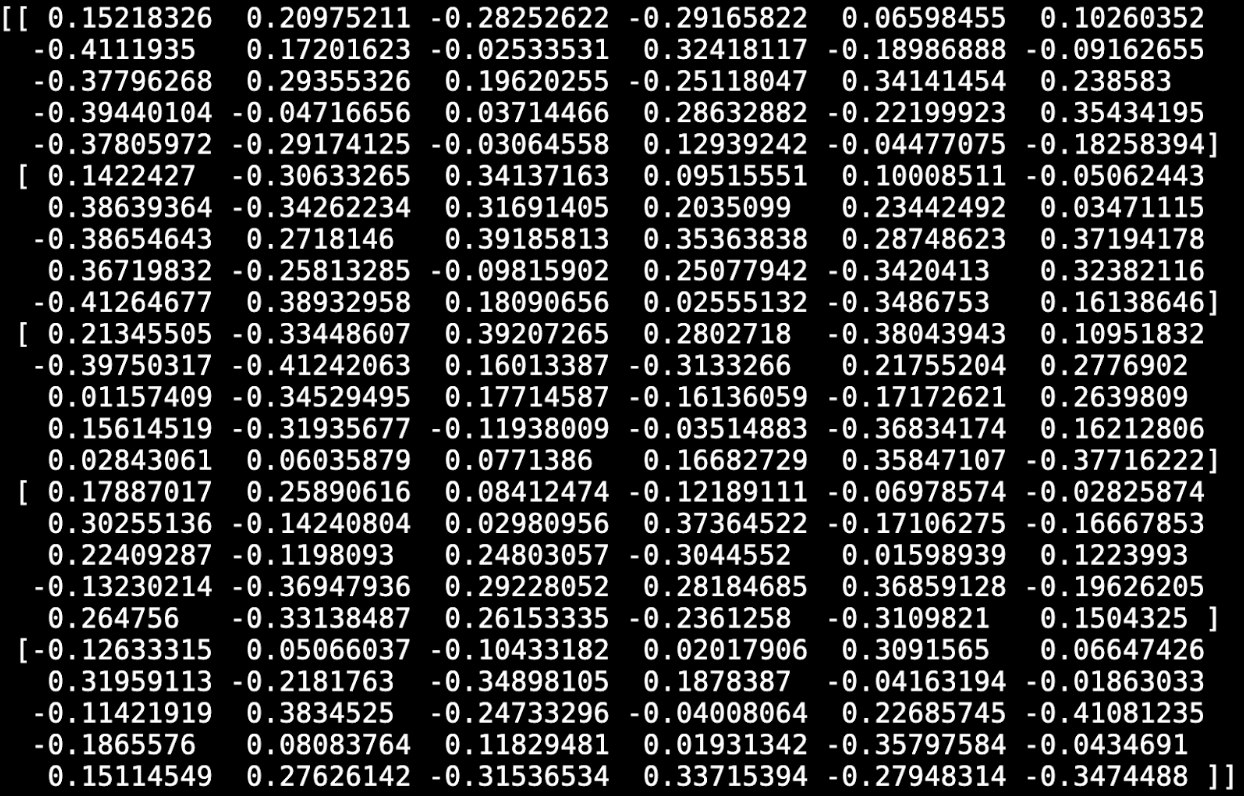
Anyone with a rudimentary understanding of the Python programming language can quickly understand the code in the first image. Even a skilled machine-learning engineer would be unable to understand the “meaning” of the weights in the second image, even if they were taken from a trained model rather than a randomly initialized one. Models are simply impossible to parse or understand without either running them or, at the very least, using sophisticated computational analysis. (As it happens, this is the reason why courts have wisely avoided repeating the Bernstein district court’s mistaken holding that transmitting object code—the literal 0s and 1s that source code is transformed into—is First Amendment-protected expression. Except in very limited cases, programmers do not delve into object code to understand how a program operates, and indeed it is a hallmark of open source that the source code itself, not just the executable, is made available for public inspection.)
One might argue that the communication of model weights should still be protected under the First Amendment because the model weights are scientific data, which is similarly non-expressive (presumably reading the raw output of a seismograph or a DNA sequencer is as unilluminating as is reading model weights). And there is a sense in which model weights are a kind of highly compressed version of the underlying training data. But even if scientific data is protected under the principle that the First Amendment “protects works which, taken as a whole, have serious literary, artistic, political, or scientific value,” it is nevertheless the case that the primary use of model weights is not as an abstract description of some underlying reality but, rather, as part of the instructions given to a computer to do something—namely, machine-learning inference.
To be sure, there may well be specific situations in which the First Amendment limits the ability of the government to restrict the discrimination of model weights. To the extent that limitations on transmitting model weights impinge on people’s ability to actually use the model, that may violate the First Amendment rights of users, just as the government could not ban the sale of a video game, even though the object code that makes up the video game executable is not itself First Amendment protected. But even if there is a First Amendment right to use machine-learning models, most users—including the hundreds of millions currently using ChatGPT, Gemini, and Claude—either run closed-source models or access them in the cloud and so don’t need access to model weights.
There may also be rare situations in which the distribution of model weights is protected not primarily to enable others to run machine-learning models but, rather, because the act of distribution itself expresses some other protected message, such as opposition to government regulation of AI. In this case, the First Amendment would apply, but the government would still prevail if the government’s interest was important and unrelated to the suppression of speech and if the restriction on the incidental speech was no greater than necessary.
None of the above discussion is to cast any doubt on the value of open-source models, which I otherwise generally support and think should be encouraged both by industry and the government. But as it stands, there is no reason to presumptively treat the distribution of model weights—as opposed to the academic research and human-readable source code used to develop them—as First Amendment-protected activity.


