What We Don’t Know About AI and What It Means for Policy
AI’s future cost and the trajectory of its development are currently unknown. Good AI policy will take that into account.


Published by The Lawfare Institute
in Cooperation With
![]()
AI is a hot topic in policy and regulatory discussions. President Biden rolled out an executive order, the Office of Management and Budget has issued guidance, there are more than 20 U.S. congressional legislative proposals, and even more in the states and internationally. Tech CEOs make broad pronouncements about the future of AI. They call AI more important than electricity or fire and say it will be used to “cure all disease,” “radically improve education,” “help us address climate change,” and “massively increase productivity.”
Lost amidst the hubris is how much is currently unknown about AI. For policymakers, two unknowns are important to keep in mind. First, no one knows how much it will cost to create future AI systems and, as a result, whether there will be only a few of those systems or whether they will be widespread. Second, no one knows the trajectory of AI development and, as a result, when and whether AI will be capable of delivering any of its potential future benefits, such as enabling cheap fusion energy, or potential risks, such as creating novel bioweapons. Unknowns about both cost and trajectory have significant implications for policymaking.
Unknowns About the Future of AI Development
Cost
The models on which generative AI systems are based are built by running algorithms over a large amount of data using huge amounts of computing power. A modern model built from scratch costs upwards of $100 million to create. The pattern of additional orders of magnitude of cost leading to additional capabilities has been robust over many years. Leading companies believe that the pattern will continue into the future of AI development, meaning that newer, more powerful models will cost billions, and soon tens of billions, of dollars to create. This has led to an abundance of fundraising for AI development and a shortage of the best chips used to create the models. If creating a competitive model will cost billions of dollars, then only a small number of entities in a tiny number of countries will be able to afford to do it.
On the other hand, ever since a relatively basic model was made publicly available in its entirety, engineers have used that model, and other publicly available models, as a basis to build more competitive systems. Some of these efforts are breathtaking in their low cost, quick turnaround, and the excellent performance of the resulting systems. For example, the Vicuna team used a relatively basic publicly available model and a set of publicly accessible conversations with a leading-edge AI system to build an AI system that they claimed performed not far beneath the leading-edge systems of that time. They did this all for only $300. Since Vicuna, more large language models have been made publicly available, and more groups around the world have started to develop off of these models. If any small group of smart engineers can create low-cost competitive models, then models are likely to be cheap and plentiful as competition drives cost down and increases capability and availability. The result will be more widespread availability of the AI systems built off those models. Of course, the greatest availability and lowest cost is open and free. If models continue to be made publicly available in their entirety, then even more people will be able to run systems off them or use them as a base to make more advanced models. If AI development is cheap, then AI systems are likely to be plentiful.
The Vicuna example was exciting, but no one knows how far this type of relatively cheap development could go. Could a Vicuna-type development surpass the leading-edge system whose chats it used for training? Could it outperform the systems based on the next generation of models in development? Will significant large language models continue to be made publicly available? Are there other, more efficient methods of advancing AI that will further reduce costs? Industry labs have hypotheses but nobody knows. As a result, nobody knows the cost of future AI innovation and, more importantly, whether that cost will mean that AI systems are few and well-guarded or many and distributed almost everywhere. Nobody, including policymakers, knows whether AI will be easily proliferated (like encryption software is), or restricted to highly resourced organizations (like nuclear weapons are), or somewhere in between.
Trajectory
The trajectory of future AI innovation is also unknown, even though the historical trend regarding new model creation is quite clear. Relatively similar algorithms using more compute and more data produce significantly more capable models. The oft-cited chart below from Our World in Data shows estimates of the amount of compute used to generate selected AI models over time.
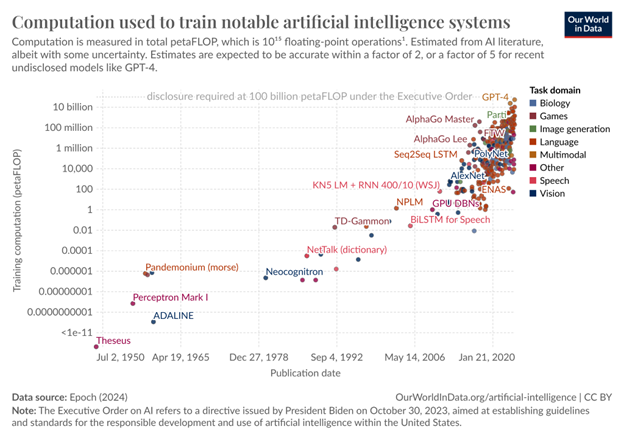
The computation axis is logarithmic, meaning that it grows exponentially. For example, GPT-3 used around 3.14 × 1023 FLOPs of computing operations in its training. A FLOP is a floating point operation, such as multiplying 2.356 by 7.2135. The important thing to note is that though creating the GPT-3 model used a lot of computing power, GPT-3.5 is estimated to have used more than eight times as much, and GPT-4 is estimated to have used more than 66 times as much, or 2.1 × 1025 FLOPs. The creation of the GPT-4 model is rumored to have taken OpenAI a number of months using a significant amount of state-of-the-art chips. While these chips are always being improved, and more and more of them are produced every year, extrapolating even three generations from GPT-4 based on that exponential growth in computing use would mean that the creation of a that new model would take a large percentage of all the computing power that might be available on Earth for a significant amount of time. That may be why the CEO of OpenAI is rumored to be raising $7 trillion to build more chip factories.
As with compute, the amount of data used for training has also increased. And models trained with significantly more data and compute have generally been more successful at a range of tests. That is the historical formula: More data and more compute lead to better capabilities. That formula has held for more than a decade, but the history of AI is the history of finding the limits of current approaches and working to come up with new ones.
Just as the general trajectory of future AI innovation is unknown, no one knows its trajectory for many specific capabilities. Scientists don’t have a way of predicting which things AI systems will become more capable of in a few generations. The creators of individual AI systems are often surprised by the new capabilities of each new model. For example, generative AI performance on a test involving addition and subtraction of three-digit numbers was not better than chance until AI performance became much better with no particular way of predicting when it would make the jump in capability. No one knows whether some of the most hopeful or scariest potential capabilities of AI systems will be real in the next set of models, a few iterations down the line, or never.
What This Means for Policy
Uncertainty over the cost and trajectory of future AI development is a challenge for policymakers but it should not postpone making effective policy. Policymakers must take cost and trajectory uncertainty into account by clearly understanding its effect on regulatory tactics, giving significant focus to already realized harms and benefits, and crafting flexible and iterative regulation that can adapt to future AI developments.
Uncertainty about future AI development cost means that policymakers cannot be certain about whether AI systems will be widespread or concentrated. That uncertainty should push policymakers not to rely on regulatory schemes that require current market dynamics to continue to exist. For example, while the voluntary commitments of AI companies that I worked on in government, or regulating current choke points is important, they in no way obviate the need for broader regulation. If AI models are cheap to build and systems proliferate, then a policy approach that is targeted at a small group of large entities and appropriate for their size will not be effective or desirable.
Uncertainty about the trajectory of AI’s future potential capabilities is a good reason to focus on the many benefits and costs these systems already entail. No one knows if the billions invested in AI systems will lead to the future benefits envisioned by many AI company leaders, but the many benefits and harms of AI systems today are known, certain and already being experienced. AI systems have underestimated black patients’ health care needs and created nonconsensual intimate images, and enabled wrongful arrests. Policy that focuses on fostering real beneficial applications of AI while cracking down on current harms remains vitally important and is unaffected by uncertainty about cost and trajectory.
As the Biden administration advocated in its Blueprint for an AI Bill of Rights, experience with real-world benefits and harms of AI should encourage policymakers to enforce existing laws against AI harms. (Disclaimer: I was part of the team that wrote the Blueprint.) As the Blueprint lays out, policymakers must be extremely skeptical of certain types of AI applications, such as those in policing, housing, and insurance, where AI could “meaningfully impact the public’s rights, opportunities, or access to critical needs.” Understanding current AI harms, policymakers should hold potential uses in these high-impact areas to a higher standard. While many AI CEOs predict that future AI systems may be better at respecting human rights, nobody knows when or if that might happen. In the meantime, laws and regulations should hold AI users and developers to that standard. The Office of Management and Budget’s Memorandum on AI is a good start at this for government use cases, but it neglects to cover some significant types of government activity and systems—and, as with all OMB memos, whether it is successful will depend a lot on how it is implemented.
Uncertainty about future AI development cost and trajectory should not stop policymakers from taking action now. Enacting policy under uncertainty is common and necessary. Such policies can be extremely effective when unknowns are taken into account. The successful regulation of fuel efficiency through the CAFE standards in the United States is a good example. Real-world fuel economy almost doubled from 1975 to 2022. In 1975, when the Energy and Policy and Conservation Act created the fuel efficiency standards, Congress did not know whether car manufacturers would be able to hit them. Rather than prescribe specific mechanisms for efficiency, Congress set targets and relied on the Department of Transportation and industry to work together to meet those targets. Importantly, the Department of Transportation was also a source of information about what was realistic. While the standards were subject to political pressures and remained stagnant from 1985 to 2011, they are a good example of an approach that could be useful for AI as well. In particular, Congress could solidify specific rights that creators or users of AI systems would need to respect. It could then empower, through additional grants of authority where needed and funding, an agency such as the Federal Trade Commission to enforce those rights and work with stakeholders to establish more specific best practices and benchmarks. Given the uncertainties, it will be extremely important that the oversight agency be agile as AI develops.
Understanding that the cost and trajectory of future AI development are open questions, policymakers should steer clear of regulation that depends on a particular answer. Regulation must be flexible enough to be able to exist in a world with few large cutting-edge models, many, or something in between. It must not be preconditioned on the existence of a future capability of AI, but instead be flexible to the emergence of different capabilities over time. Moreover, policymakers should not be looking to develop the final word on AI regulation. AI development is likely to continue to be surprising. Iterative regulation based on developing understanding is much more likely to be successful.
Thank you to Dr. Alondra Nelson, Nik Marda, Dr. Marc Aidinoff and Dr. Tim Robertson for reading drafts of this piece.

.png?sfvrsn=66bc5b35_5)
